
“Learning and innovation go hand in hand. The arrogance of success is to think that what you did yesterday will be sufficient for tomorrow”
William Pollard
We regularly run community-wide modelling challenges at Full Stack Modeller. One of my key areas of focus for the foreseeable future will be training our members for the FMWC and the Excel Battle events (if they wish to take part - it's not mandatory!). As a result of this, the last challenge we ran as a community was one of the old Excel Battle challenges based on the game of Tetris. As ever, these problem solving challenges offer a really unique opportunity for modellers to test their skills out under pressure, and to learn new skills.
The submissions we received were so brilliantly varied that I've decided to share them all here with you. Each submission follows a different approach (as you might expect in Excel!), and they range from what I'd call pretty "traditional" approaches, all the way through to some cutting-edge LAMBDA magic!
My aim here is to simply share them with you in the hope that you take something useful from them. My sneaky secondary aim is to wet your appetite for what we do at Full Stack. It's a membership journey that will transform your modelling capabilities, with a community of supportive professionals from all over the world ready to step in if you ask for help.
The Challenge
You can download the original challenge file from the FMWC website here, and you can download each of the submissions from our members here.
Read through the challenge description on the Case tab first.
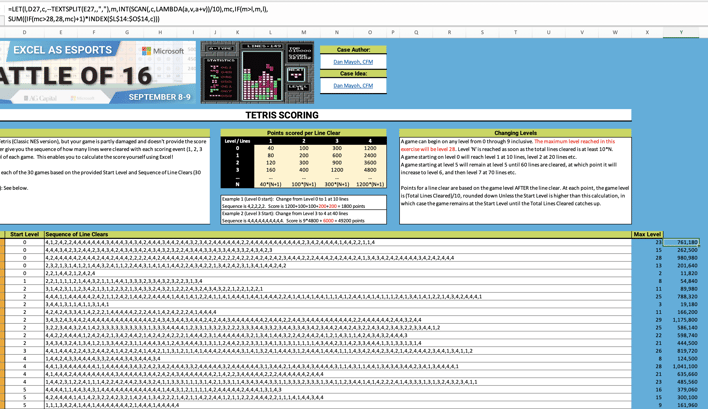
To summarise to challenge, points are earned by clearing lines (imagine you've got your old Gameboy in front of you. If you don't know what a Gameboy is…well, I'm jealous… Google it). The number of points you earn depends on the number of lines you clear for each line clearance step (line clearances can be from 1 to 4 for each step), and the level you're at for each turn. You start at a level from 0 to 28, and the points scale up at each level for each set of lines cleared.
The challenge template has 30 individual "rounds" for you to calculate an answer for, with a series of lines cleared as a sequence in each round, plus a stated starting level.
You've got to deal with the initial challenge of pulling the line clearance numbers you'll need for your calcs from data held in one cell, and then you've got to work out the logic to get you to your total points value for each of the 30 rounds.
If you've got time, have a go at this yourself before you look at the solutions below. I'm not covering the bonus question here - just the core solution for the 30 rounds of Tetris.
The Solutions
Thank you to Sarah, Stephanie, Charles, Bo and Craig for allowing me to share these solutions. This is just one of so many great examples I've seen of skills being showcased for the benefit of the community at Full Stack.
I suggest you download each of the solution files from the link above, and walk through them as you read through my notes below.
Submission 1 - Sarah Fraser
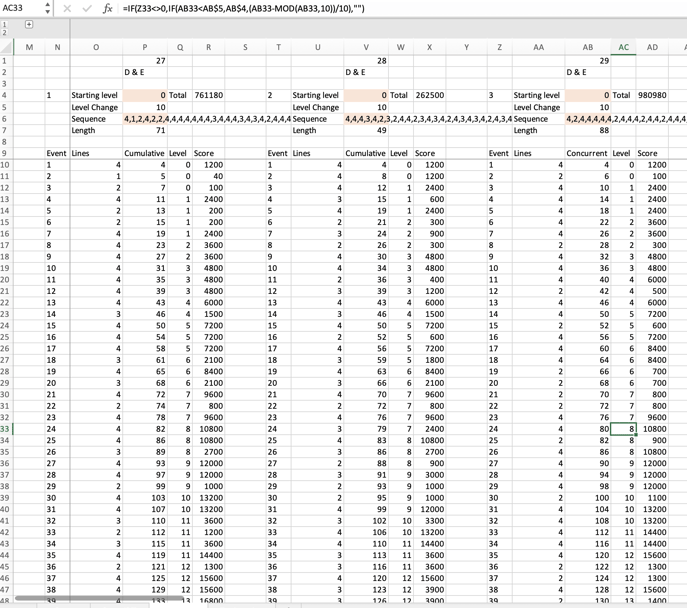
Sarah's been competing in these Excel Battles for a while now, and she's showcasing some brilliant problem-solving skills here.
Sarah's workings are all held on a separate Workings tab (top marks from the Full Stack faculty for best practice modelling there!).
Sarah starts by using TRANSPOSE and TEXTSPLIT to generate the list of line clearances in individual cells vertically. She then calculates the cumulative number of lines cleared, then leans on MOD to calculate the current level achieved as each new line clearance step is passed. Finally, she uses an INDEX with two MATCHs to pick up the relevant points for each line clearance step.
The tricky part for Sarah is that she chose to manually replicate this logic 30 times to get to the answer for each of the 30 rounds. It works, and half the challenge in these battle events is just getting to a logical solution that works, but there are ways to do this faster.
Submission 2 - Stephanie Annerose
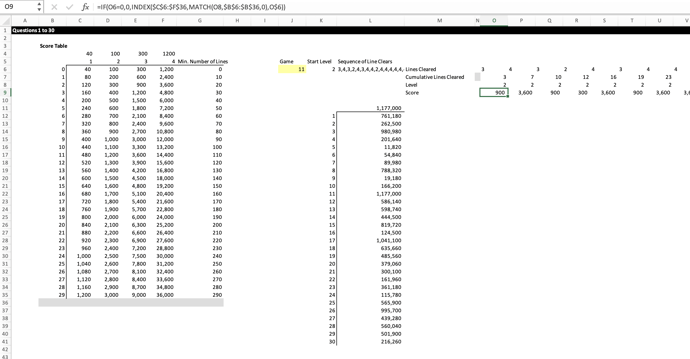
Stephanie is a regular competitor at these events, and she's been in a few of the live, on-screen battles already!
Stephanie's calculations are held on a tab called Questions 1 to 30. The core logic itself is very similar to Sarah's, even if it looks quite different at first glance.
Stephanie has used TEXTSPLIT to profile the line clearances horizontally as her first step. She then calculates the cumulative line clearances. Next, she uses INDEX and MATCH to first pull through the relevant level, and then to calculate the score for each line clearance step.
The beauty of Stephanie's approach is the use of a one-way Data Table to generate the answers for all 30 rounds, based on the logic she calculated just once. Data Tables are incredibly powerful, and a vital feature to master if you want to do well at these battles. Knowing them can help avoid repetitive copy / paste logic steps (like the ones Sarah had to carry out).
Submission 3 - Charles Poulain
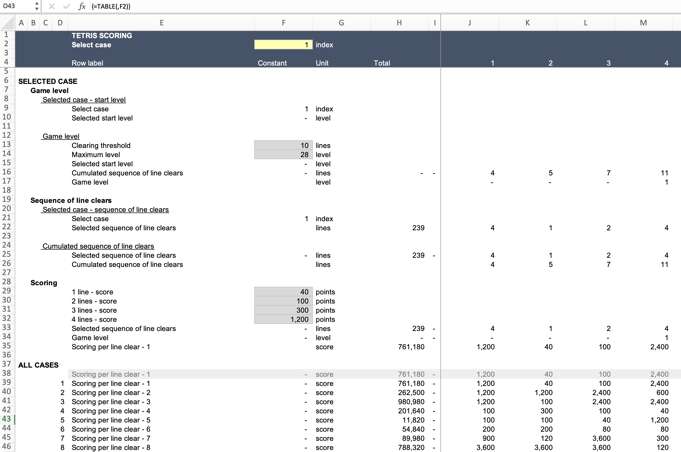
Charles has been with Full Stack since we first opened up, and he's taken to the FAST Standard more than any other member. So it was no surprise for me to see that his solution was about as FAST-based as it could be!
His calculations are set out on a tab called Model. His calculation structure is really neat and easy to follow. He's using FAST's calculation blocks where possible, which is, in my opinion, one of the best ways to make modelling logic relatively straight-forward to understand.
He's using ROUNDDOWN to calculate the relevant game level for each line clearance step. He's using TEXTSPLIT to generate the list of line clearances in individual cells horizontally, with INDEX tucked in there to get his model set up for the Data Table he turns to next.
The one-way Data Table Charles uses is unusual because he's actually generating every value for every line clearance horizontally, for every one of the 30 rounds, with his one Data Table. That's him thinking as a FAST modeller - trying to share as much insight into the logic and the numbers as possible. Those who dislike FAST would argue it adds way too much noise (rows, numbers…), but I've always felt this "drawback" of FAST is outweighed by the insight the approach offers to anyone trying to follow the logic.
Submission 4 - Bo Rydobon
Bo is very well known on the battle circuit, and he's an absolute whiz at solving problems. One of the unique skills he possesses is solving things in one cell (often leaning on LAMBDAs and LET). He's no one-trick pony though. He's equally adept at Power Query coding. All of this blows my mind when I consider that he's only been using Excel for about 5 years!
Bo's one-cell solution can be found in column Y on the Case tab itself. If you've not used LET and LAMBDA before, this (probably poor) attempt to explain the logic may confuse you more than it helps.
LET is used to name and then define the calculation logic of parameters. Each parameter is first named, and then the calculation logic for that parameter comes next (after a comma). The final element of the LET function is for the final calculation, which calls on many of the parameters that have been defined. LET is perfect for simplifying complex calculations that are native to a single cell. As this is one of Bo's specialities, LET is something he turns to a lot! As a FAST modeller, I don't use LET much because I'm used to breaking out logic steps into multiple rows. But I'm not knocking it - for this sort of approach, it's a total game-changer.
Where things get complex is his use of the LAMBDA helper function, SCAN, within one of the parameter calculations within his LET. The SCAN function allows him to pass each line clearance step number through the LAMBDA, which he's set up to calculate a cumulative line clearance total and divide by 10 (with the INT function ensuring he ends up with the correct whole number for the level achieved for each line clearance step). The final part of his formula uses INDEX to pull through the relevant scores for each line clearance step.
I'm still on my own journey getting to grips with LAMBDAs (which I'll have to move quickly with as I'm presenting a paper for Craig Hatmaker in July at the EUSPRIG conference in London… on LAMBDAs!). Watching Bo (and Craig) work their magic is speeding up this journey for me immensely.
Submission 5 - Craig Hatmaker
Craig is just on another level. I'll probably never fully get to grips with some of the ways he can solve problems (that's a compliment by the way Craig). He first came to my attention with his Multi-Dimensional Table Based modelling system. More recently he's been doing some crazy magic with Named LAMBDA functions. I've had hours of one-to-one time with Craig to try to get my head around this methodology. I have to rest my brain after every session. That's a reflection of my lack of programming experience and intelligence, not a reflection of his approach. It's complex, if you're not used to coding, but the result is often a really simple named-LAMBDA function for users to take advantage of.
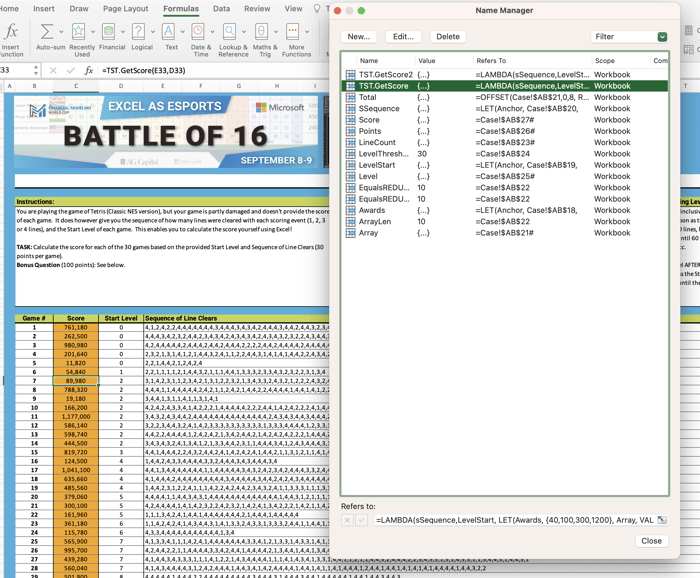
What Bo does with LET and LAMBDA in an Excel cell, Craig does in the Name Manager. The result of this is a LAMBDA function embedded within a Named Range, which ends up being a new, custom function he can call upon anywhere in Excel just by calling up the Named Range.
Craig's calculation is in the actual solution cells on the Case tab, in column C (the cells with orange fill). This is the calculation solution you, as a viewer, see in native Excel: TST.GetScore(E27,D27).
That's it! Bonkers right? Now look in the Name Manager at the reference calculation within that TST.GetScore Name. It's pretty much the same logic Bo had in his native Excel cell, all held within the Name Manager.
The challenge you'll hear from traditional modellers is that this becomes something of a "black box". Craig has a view on this, which I understand. It comes down to the split between Users and Developers of modelling logic. If you just have to use the LAMBDAs that have been created, it makes your life simpler so long as you have confidence the LAMBDA logic is correct. But the "black box" argument is, in my opinion, the biggest hurdle proponents of this approach have to overcome. If experienced modellers have a tried and tested way of working, that offers other users and viewers of models an easy way to follow the logic, then it's going to be hard to get them to change their methodology without seeing clear and unique benefits coming from that change.
But there's more!
Craig's going even further with his LAMBDA position though! He's put together a paper for EUSPRIG that argues for the creation and wider use of component-based LAMBDAs that general Excel users could download from the internet and use quickly and effectively. I'm very honoured he's asked me to present this paper for him in London. I only said "yes", despite my lack of experience with LAMBDAs, because I think the pressure to deliver a good presentation on something that's not strictly within my comfort zone will ultimately push me to develop my skills faster.
If you'd like to join the EURSPRIG event in July, follow this link.
If you'd like to join us at Full Stack, check out our new All-In Bundle offer. It's pretty bonkers in terms of the value we're giving away. It's the coming together of Full Stack Modeller, the Financial Modeling Institute (FMI), Maven Analytics, and the team behind the Financial Modeling World Cup and the Excel Battle Series. We have a special offer running until the end of July - so don't miss out!
I hope this blog and these solutions give you some nice Excel tips and tricks to take away and master. Reach out to me if you have any questions.
Giles


